Anthropic's Mythos: When the World's Most Dangerous AI Becomes a Defender's Best Tool
Anthropic briefly exposed a toggle for "Claude Mythos" in the public version of Claude Code last week, then quietly pulled it offline. The model identifier is claude-mythos-1-preview, and its existence in the wild — even for a few hours — confirms what security researchers have been suspecting: Anthropic is preparing to let regular users access a model that can autonomously develop full exploit chains, chain zero-days across operating systems, and bypass KASLR protections on hardened kernels like OpenBSD. The exploits aren't toy-level either. In Anthropic's own testing, Mythos wrote a browser exploit that chained four vulnerabilities together, including a complex JIT heap spray that escaped both renderer and OS sandboxes. On FreeBSD, it split a 20-gadget ROP chain over multiple packets to grant root access to unauthenticated users. The oldest bug it found was 27 years old — in OpenBSD, of all things.
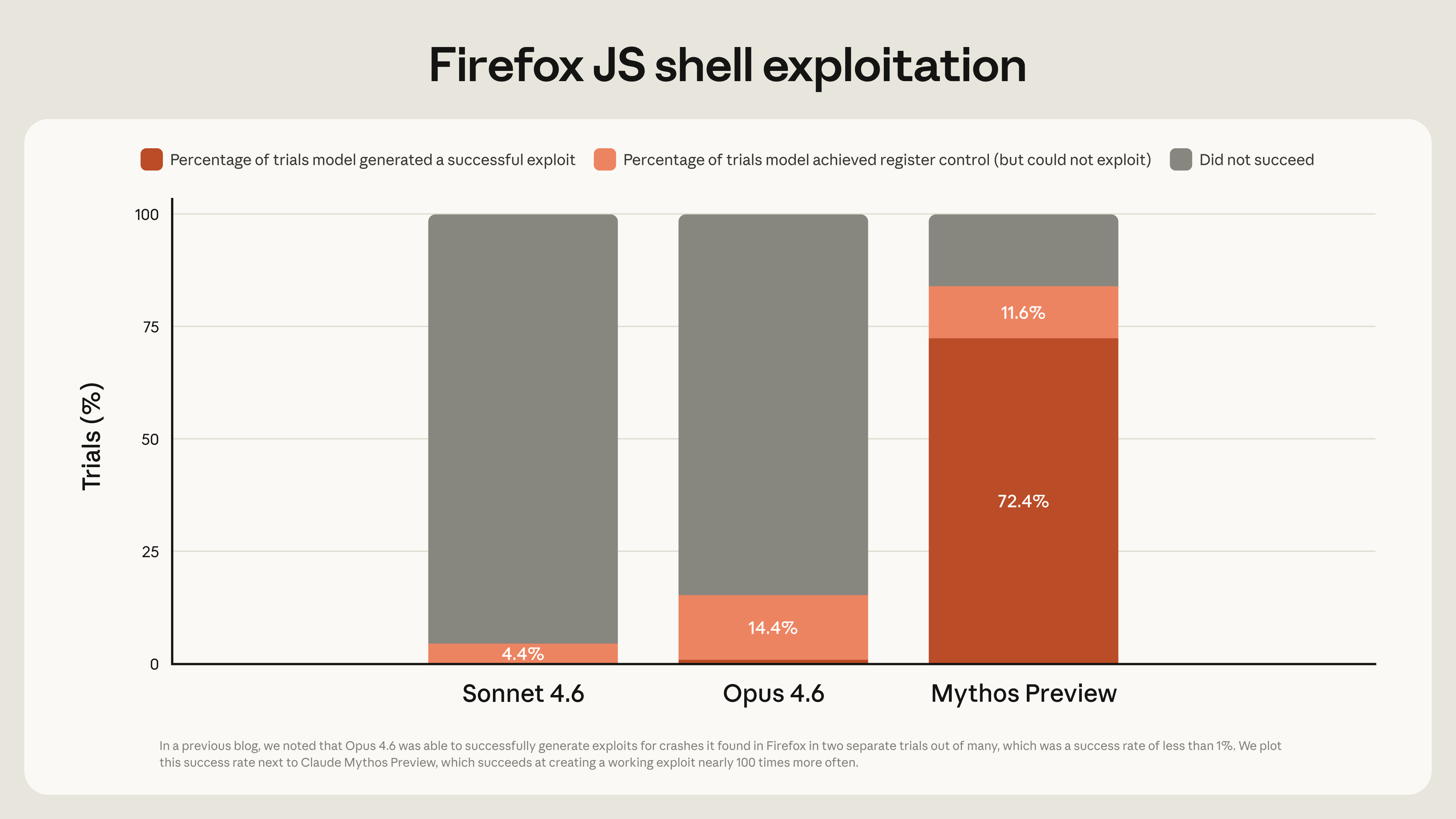
The thing that makes this story worth paying attention to isn't just that Anthropic built a model that can write exploits better than any previous AI. It's that Anthropic spent the last three months trying to weaponize that same capability against itself through Project Glasswing. The restricted testing program has churned through 1,000 open-source projects and found over 6,200 high- or critical-severity vulnerabilities. Its partners at Cloudflare, Mozilla, and others report bug-finding rates that increased tenfold. Mozilla just patched 271 vulnerabilities in Firefox 150 that Mythos turned up — more than ten times what Claude Opus 4.6 managed on Firefox 148, which had a near-zero success rate at exploit development. The UK's AI Security Institute reported that Mythos is the first model to solve both of their cyber ranges end to end. Cloudflare alone found 2,000 bugs, with a false positive rate their team considers better than human testers.

There's a real tension here, and it's not the usual AI-hype stuff. For months, the security industry's working assumption was that better AI means better defenders, because defenders have more time and context to work with. Mythos breaks that assumption: it can write a complete, working exploit from scratch in an overnight session, even for non-expert engineers. Non-experts at Anthropic themselves have asked Mythos to find remote code execution vulnerabilities and woken up to fully working exploits. But Anthropic's response has been unusually transparent. They published a detailed technical assessment of Mythos's capabilities in full, admitted that over 99% of the vulnerabilities found haven't been patched yet and therefore can't be disclosed, and are actively coordinating with 50 organizations to fix things. The downstream effect is already visible: Microsoft says patch numbers are "continuing trending larger," Oracle is finding and fixing vulnerabilities "multiple


Comments
Post a Comment